Beraber C# ile bot yapalım (=Web Sitelerinden Veri Çekelim)
Websitelerinden kendi kodumuz ile veri çekelim ve yayınlayalım, ne dersiniz?
Internet sayfalarını kod yardımı ile okuyabilmek ve dönen değerleri kullanabilmek için halihazırda iki adet sınıfımız mevcut:
- HttpWebRequest
- HttpWebResponse
Bu iki sınıf da System.Net namespace i altında bulunuyor. Dolayısıyla sayfamızın yukarısına using ifadesini eklemeyi unutmuyoruz.
Neyse öncelikle; sayfayı baştan sona HTML olarak indirip bir string değişken içerisine atacak bir metot yazalım.
private static string BilgiCek(string url)
{
StringBuilder sb = new StringBuilder();
byte[] buf = new byte[8192];
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream resStream = response.GetResponseStream();
string tempString = null;
int count = 0;
do
{
count = resStream.Read(buf, 0, buf.Length);
if (count != 0)
{
tempString = Encoding.UTF8.GetString(buf, 0, count);
sb.Append(tempString);
}
}
while (count > 0); // any more data to read?
return sb.ToString();
}
Bu metotla, sayfayı 8k lık dilimler halinde indiriyoruz. Bazen aynı işi yapan daha kısa bir koda da denk gelebilirsiniz.
private static string BilgiCek(string url)
{
WebRequest istek = HttpWebRequest.Create(url);
WebResponse cevap = istek.GetResponse();
StreamReader donenBilgiler = new StreamReader(cevap.GetResponseStream());
return donenBilgiler.ReadToEnd();
}
İstediğinizi kullanabilirsiniz. Aralarındaki farkı araştırmak size kalmış.
Şimdi gelelim ana metoda. Önce kendimize bir hedef seçelim. Mesela web sitesinin <title>...</title> bilgisini çekmeye çalışalım.
İstediğimiz bilgiyi okuyamama ihtimaline karşı, kodumuzu önce satır sonu karakterlerinden temizleyelim, sonra da RegExp yardımı ile verimizi çekelim:
while (tumu.IndexOf(Environment.NewLine) > -1)
{
tumu = tumu.Replace(Environment.NewLine, " ");
}
string title = "";
Match m = Regex.Match(tumu, "<title[^>]*>(.*?)</title>",
RegexOptions.CultureInvariant | RegexOptions.IgnoreCase);
if (m.Success)
{
tumu = m.Groups[1].Value;
title = tumu.Trim();
}
Şimdi de bir örnek yapalım:
static void Main(string[] args)
{
string url = "http://www.daltinkurt.com/Gunluk/70-Sitenize-URL-kisaltma-servisi-ekleyin.aspx";
string tumu = BilgiCek(url);
while (tumu.IndexOf(Environment.NewLine) > -1)
{
tumu = tumu.Replace(Environment.NewLine, " ");
}
string title = "";
Match m = Regex.Match(tumu, "<title[^>]*>(.*?)</title>",
RegexOptions.CultureInvariant | RegexOptions.IgnoreCase);
if (m.Success)
{
tumu = m.Groups[1].Value;
title = tumu.Trim();
}
Console.WriteLine(title);
}
Çıktımız:
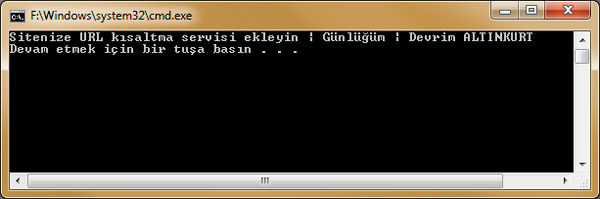
Şimdi de site içeriğinden bilgi almaya çalışalım.
Örnek sayfamız http://www.mgm.gov.tr/tarim/zirai-rapor.aspx olsun.
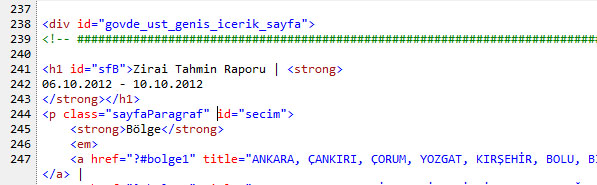
<h1> .. </h1> tagi içeriğini okumaya çalışalım. Bunu seçme nedenim; 1) içinde başka tag kullanılmış. 2) 2 satırdan oluşuyor, yani bir adet "yeni satır" karakterini (Environment.Newline) temizlememiz 3) son aşamada da split etmemiz gerekiyor.
Buradan buyrun:
static void Main(string[] args)
{
string url = "http://www.mgm.gov.tr/tarim/zirai-rapor.aspx";
string html = BilgiCek(url);
string tarihStr = @"<h1 id=""sfB"">";
int pos1 = html.IndexOf(tarihStr);
int pos2 = html.IndexOf("</h1>", pos1);
string tarih = html.Substring(pos1, pos2 - pos1);
tarih = ToClearText(tarih);
string[] pars = tarih.Split("|".ToCharArray(), StringSplitOptions.RemoveEmptyEntries);
Console.WriteLine("-> " + pars[0].Trim() + " <-");
Console.WriteLine("-> " + pars[1].Trim() + " <-");
}
Ekran çıktısı:
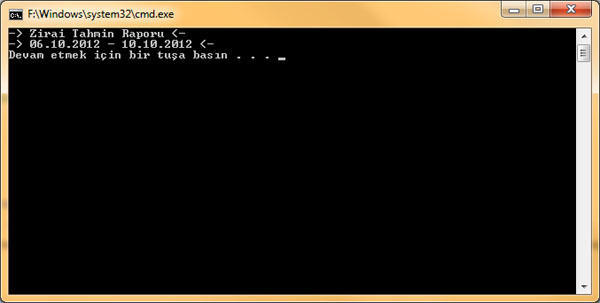
Bu yöntem sayesinde, gözünüze kestirdiğiniz bir siteden "isim sözlüğü", "atasözleri", "İngilizce-Türkçe sözlük" gibi hazırlanması aylar alacak bilgileri kısa zamanda toplayabilirsiniz.
Herkese kolay gelsin.
Not: ToClearText(string) metodu da nereden çıktı diyenlere:
public static string ToClearText(string text)
{
return Regex.Replace(text, @"<(.|\n)*?>", string.Empty);
}
#bot #cs #CSharp #C #veri #bilgi #veri-çekme #bilgi-çekme #HttpWebRequest #HttpWebResponse #title
